
BASEMENT
모델 성능 평가 척도, ROC 커브 본문
1. 모델 성능 평가 척도
모델의 예측결과와 성능을 살펴볼 수 있는 척도
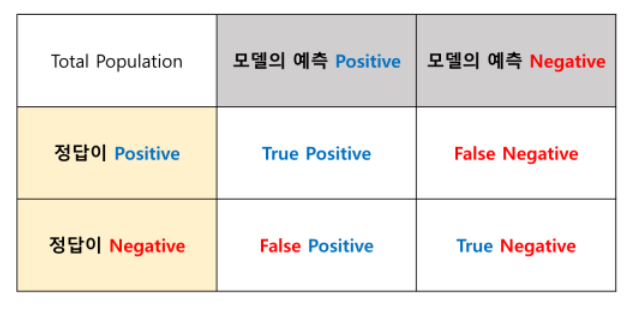
1. Confusion Matrix

- 실제값 : 데이터의 실제 카테고리. y_test
- 예측값 : 모델이 분류, 예측한 데이터의 카테고리. y_pred
- TP : 실제 yes 카테고리의 데이터 중 모델이 yes 카테고리로 예측한 데이터의 건 수
- FN : 실제 yes 카테고리의 데이터 중 모델이 no 카테고리로 예측한 데이터의 건 수
- FP : 실제 no 카테고리의 데이터 중 모델이 yes 카테고리로 예측한 데이터의 건 수
- TN : 실제 no 카테고리의 데이터 중 모델이 no 카테고리로 예측한 데이터의 건 수
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
y_test = [0,0,0,0,0,1,1,1,1,1]
y_pred = [0,1,0,0,0,0,0,1,1,1]
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)
plt.matshow(confusion_matrix)
plt.title('Confusion Matrix')
plt.colorbar()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
2. Accuracy (정확도)
모델이 정확하게 분류 또는 예측하는 데이터의 비율
Accuracy 모델은 한계가 있어서 성능을 측정하는 척도로 적합하지 않음
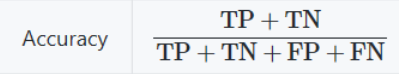
3. Precision (정밀도)
모델이 검출한 데이터 중 올바르게 검출된 데이터의 비율

4. Recall (재현율)
실제 해당 데이터중 모델이 올바르게 검출한 데이터의 비율

5. F1-Measure
Precision과 recall은 모델의 성능을 객관적으로 판단하기에 부족함
Precision과 recall 수치의 trade-off 관계를 통합해 하나의 수치로 정확도를 도출함

6. Overfitting & Underfitting
1) 오버피팅 (Overfitting)
- 학습 오류가 테스트 데이터셋에 대한 오류보다 아주 작은 경우
- 너무 세밀하게 학습 데이터 하나하나를 다 설명하려고 하다보니 정작 중요한 패턴을 설명할 수 없게 되는 현상
2) 언더피팅 (Underfitting)
- 모델이 너무 간단해서 학습 오류가 줄어들지 않는 경우
- 학습 데이터가 모자라거나 학습이 제대로 되지 않아서 트레이닝 데이터에 가깝게 가지 못하는 현상

2. ROC Curve
Binary Classifier System(이진 분류 시스템)에 대한 성능 평가 기법

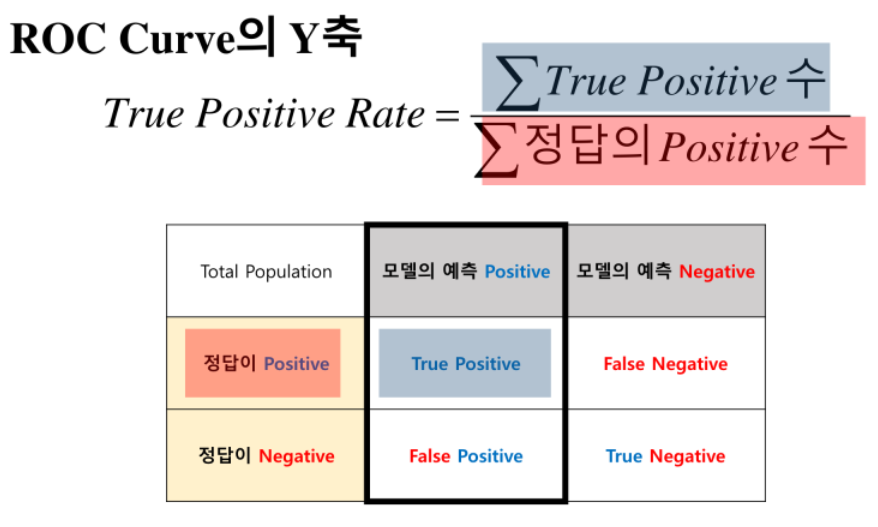
1. Sensitivity (민감도)
TPR (True Positive Rate)
실제 yes 클래스 데이터 중 모델이 yes클래스로 예측한 데이터의 비율
TP / (TP+FP)
2. Specificity (특이도)
TNR (True Negative Rate)
실제 yes 클래스 데이터 중 모델이 no 클래스로 예측한 데이터의 비율
TN / (TN+FP)
3. 1 - Specificity
FPR (False Positive Rate)
실제 no 클래스 데이터 중 모델이 yes 클래스로 예측한 데이터의 빙ㄹ
FPR = FP /N
4. ROC Curve
- 모델이 yes 클래스를 정확하게 예측할수록 sensitivity 값이 높아짐
- 빨간색 곡선은 랜덤으로 예측한 것으로 성능이 가장 나쁜 경우에 해당
- 곡선이 굽어지면 굽어질수록 AUC가 넓어지므로 더욱 정확한 모델

5. ROC Curve 예제
from yellowbrick.classifier import ROCAUC
visualizer = ROCAUC(log_reg, classes=[0,1], micro=False, macro=True, per_class=False)
visualizer.fit(train_x, train_y)
visualizer.score(train_x, train_y)
visualizer.show()
'Programming > Machine Learning' 카테고리의 다른 글
| Naive Bayes (나이브 베이즈) (0) | 2020.10.05 |
|---|---|
| KNN 알고리즘 (0) | 2020.09.27 |
| 로지스틱 회귀분석 (0) | 2020.09.27 |
| Sklearn과 선형회귀분석 (0) | 2020.09.27 |
| 데이터 전처리 (0) | 2020.09.27 |

